Top 10 PDF Parsing Tools to Boost Your AI Agent Workflow
As AI technology advances, building sophisticated AI agents has become a priority for many organizations. One crucial aspect of creating effective AI agents is their ability to process and understand various types of data, including information contained in PDF documents. This article explores how to utilize AI-powered PDF parsing and data extraction techniques to enhance your AI agents’ capabilities.
Why PDF Parsing Matters for AI Agents
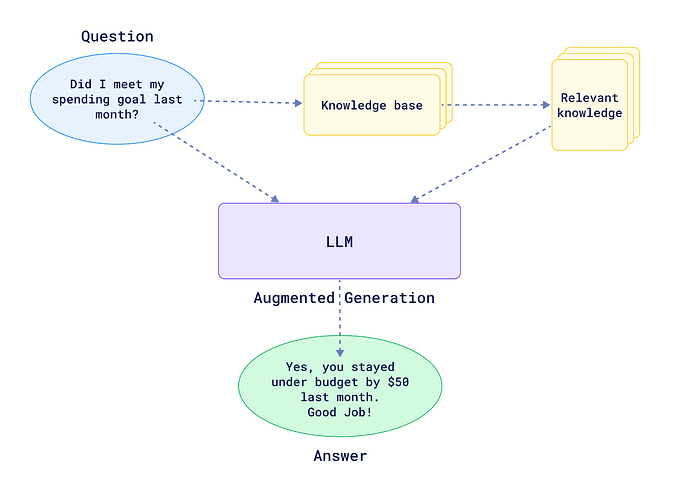
AI agents often need to interact with a wide range of information sources to perform their tasks effectively. PDFs are a common format for storing and sharing important business documents, research papers, and other valuable data. By incorporating advanced PDF parsing capabilities, your AI agents can:
- Define Clear Objectives: Identify specific use cases for PDF parsing, such as extracting financial data, analyzing research papers, or processing legal documents.
- Choose Appropriate Tools: Select an AI platform with OCR capabilities, support for various PDF formats, and integration with AI frameworks.
- Develop Knowledge Base: Create a structured repository of information extracted from PDFs to support AI decision-making.
- Implement Data Preprocessing: Establish a robust pipeline for document cleaning, text extraction, and structure identification.
- Train and Optimize: Use diverse PDF content to train the AI agent, fine-tune models for domain-specific terminology, and implement continuous learning.
- Ensure Security: Implement strong measures like encryption, access controls, and compliance with data protection regulations to safeguard sensitive information.
Top 10 PDF Parsing Tools for Your AI Agent Workflow
1. Doc2x: The All-in-One Converter
Doc2x stands out as a versatile PDF parsing tool that excels in converting PDF files to various formats, including Markdown, LaTeX, and DOCX. Its strength lies in its ability to accurately parse complex elements such as:
- Layout and formatting
- Mathematical formulas
- Tables
- Images and charts
What sets Doc2x apart is its superior performance in handling documents with intricate tables and formulas. Many leading AI companies in China have adopted Doc2x for its exceptional processing capabilities, outperforming even Mathpix in both Chinese and English document handling.
2. GPTPDF: Open-Source Simplicity
GPTPDF is an impressive open-source project that achieves near-perfect parsing of PDF elements in just 293 lines of code. Its capabilities include:
- Layout analysis
- Mathematical formula extraction
- Table recognition
- Image and chart processing
The tool leverages the PyMuPDF library to identify non-text areas in PDFs and uses advanced visual AI models like GPT-4o for parsing. While its current performance is limited by GPT-4o’s capabilities, future iterations promise even more impressive results.
3. RAGFlow: Deep Document Understanding
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that takes a unique approach to document parsing. To combat hallucination issues, the project employs an innovative “deep document understanding” method. RAGFlow supports a wide range of document types, including:
- Word documents
- PowerPoint presentations
- Excel spreadsheets
- Plain text files
- Images and scanned documents
- Structured data
- Web pages
Its versatility extends to parsing various document templates, such as invoices, resumes, and financial reports, making it an excellent choice for diverse business needs.
4. Mathpix: The Mathematician’s Choice
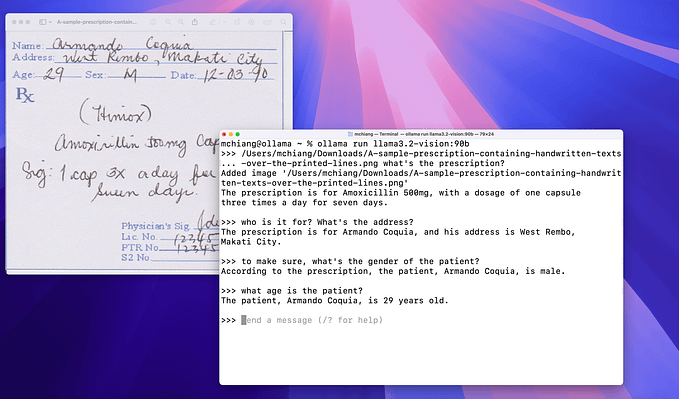
Mathpix has gained a reputation for its exceptional mathematical parsing capabilities, rumored to be the secret behind Claude AI’s strong math skills. This tool offers comprehensive support for:
- Text extraction
- Mathematical and chemical formula recognition
- Handwriting recognition
- Table parsing
- Foreign language support
- Full PDF document conversion
Mathpix can output content in LaTeX, Markdown, and Word formats, making it invaluable for researchers and academics. It also features a Google-like search functionality, enhancing its utility for document analysis.
5. PDFlux: AI-Powered Extraction and Analysis
PDFlux specializes in extracting tables and text from both PDFs and images. Its standout feature is the AI-powered ability to:
- Generate summaries
- Perform intelligent searches
- Rewrite content
- Translate text
This combination of extraction and AI-driven analysis makes PDFlux a powerful tool for professionals who need to quickly digest and repurpose information from complex documents.
6. Pix2Text: Open-Source Multilingual Support
Pix2Text is an open-source solution that shines in its multilingual capabilities. It can recognize various elements within images, including:
- Layout
- Tables
- Images
- Text
- Mathematical formulas
The tool outputs content in Markdown format and can convert entire PDF files, regardless of whether they contain scanned images or other formats. Its flexibility and open-source nature make it an attractive option for developers and researchers.
7. TextIn: Optimized for Business Documents
TextIn specializes in recognizing text information from documents or images and reconstructing it in a logical reading order. It’s particularly adept at handling:
- Annual reports
- Legal documents
- Letters and correspondence
- Contracts
Compatible with both scanned documents and electronic PDFs, TextIn is an excellent choice for businesses dealing with a high volume of standardized documents.
8. Tencent Cloud Document Recognition
Tencent’s offering in the PDF parsing space focuses on converting images or PDF files into Markdown format. It excels in:
- Table recognition
- Formula extraction
- Image handling
- Text conversion
A key feature is its ability to rearrange content into a logical reading order, making it easier to consume and analyze large documents.
9. Marker: Optimized for Academic Content
Marker is an open-source tool that supports multiple languages and document types. What sets it apart is its optimization for:
- Books
- Scientific papers
This specialization makes Marker an invaluable resource for academics, researchers, and students who frequently work with scholarly content.
10. PaddleOCR: Specialized Table Recognition
PaddleOCR, developed by Baidu, offers a unique end-to-end table recognition system. It’s particularly adept at:
- Accurately predicting table locations in documents
- Extracting table contents from papers and reports
This specialized focus on table recognition makes PaddleOCR an excellent choice for data analysts and researchers who frequently work with tabular data in PDFs.
Before we conclude, let’s talk about something that we all face during development: API Testing with Postman for your Development Team.
Yeah, I’ve heard of it as well, Postman is getting worse year by year, but, you are working as a team and you need some collaboration tools for your development process, right? So you paid Postman Enterprise for…. $49/month.
Now I am telling you: You Don’t Have to:

That’s right, APIDog gives you all the features that comes with Postman paid version, at a fraction of the cost. Migration has been so easily that you only need to click a few buttons, and APIDog will do everything for you.
APIDog has a comprehensive, easy to use GUI that makes you spend no time to get started working (If you have migrated from Postman). It’s elegant, collaborate, easy to use, with Dark Mode too!

Want a Good Alternative to Postman? APIDog is definitely worth a shot. But if you are the Tech Lead of a Dev Team that really want to dump Postman for something Better, and Cheaper, Check out APIDog!
Conclusion
Whether you’re dealing with complex mathematical formulas, multilingual documents, or intricate tables, these top 10 PDF parsing tools offer powerful solutions to streamline your document analysis workflow.
As Agentic AI landscape continue to advance, we can expect even more sophisticated parsing capabilities in the future. For now, these tools represent the cutting edge of PDF analysis, offering unparalleled accuracy and efficiency in extracting valuable information from digital documents.