How to Run Ollama on Google Colab
In the rapidly evolving landscape of artificial intelligence and machine learning, large language models (LLMs) have become increasingly popular and powerful tools. However, running these models locally often requires significant computational resources that may not be readily available to everyone. This is where Google Colab and Ollama come into play, offering a solution that allows users to harness the power of LLMs without the need for expensive hardware. In this comprehensive guide, we’ll explore how to run Ollama on Google Colab, providing you with a step-by-step approach to leveraging these cutting-edge technologies.
Before we get started, Let’s talk about something that we all face during development: API Testing with Postman for your Development Team.
Yeah, I’ve heard of it as well, Postman is getting worse year by year, but, you are working as a team and you need some collaboration tools for your development process, right? So you paid Postman Enterprise for…. $49/month.
Now I am telling you: You Don’t Have to:
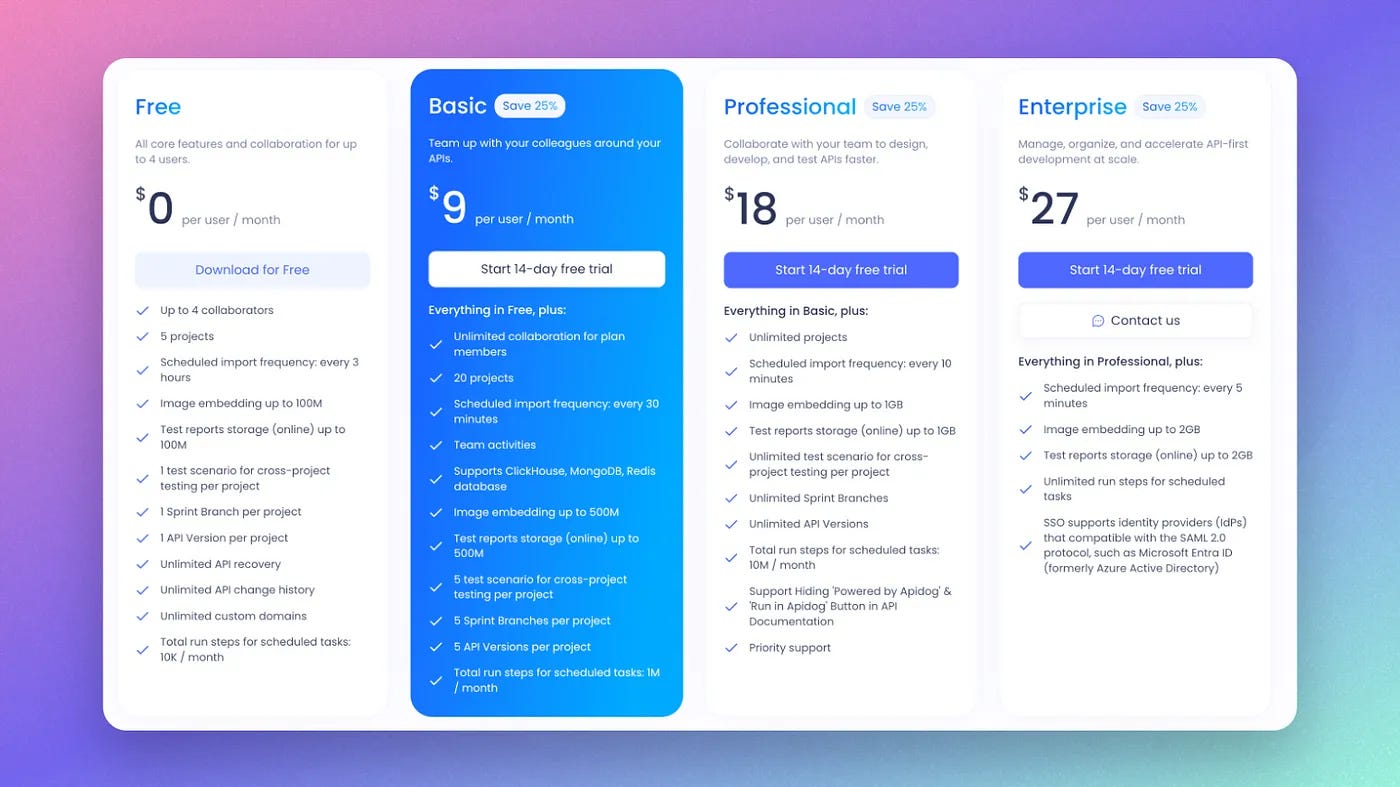
That’s right, APIDog gives you all the features that comes with Postman paid version, at a fraction of the cost. Migration has been so easily that you only need to click a few buttons, and APIDog will do everything for you.
APIDog has a comprehensive, easy to use GUI that makes you spend no time to get started working (If you have migrated from Postman). It’s elegant, collaborate, easy to use, with Dark Mode too!
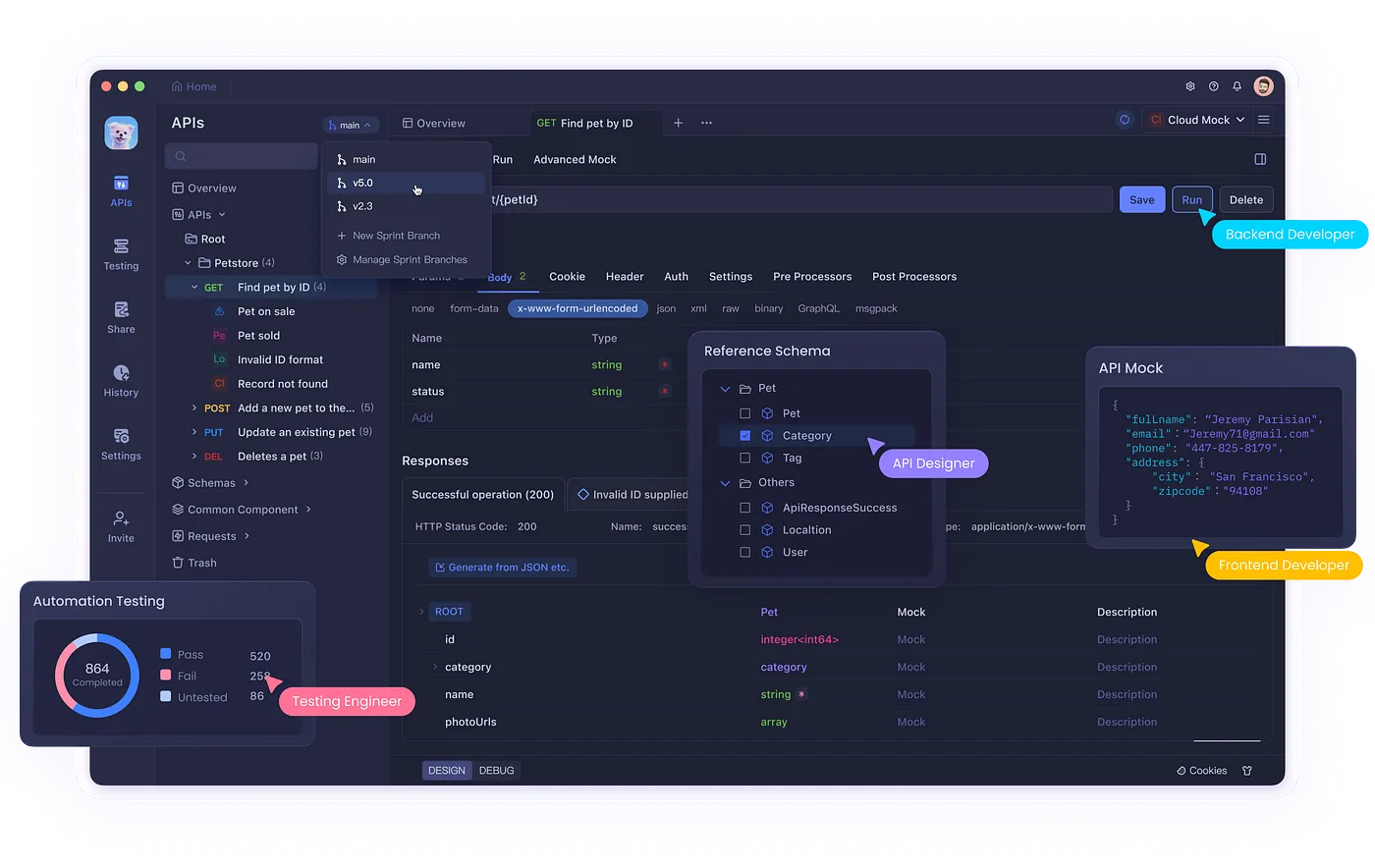
Want a Good Alternative to Postman? APIDog is definitely worth a shot. But if you are the Tech Lead of a Dev Team that really want to dump Postman for something Better, and Cheaper, Check out APIDog!
Before diving into the setup process, it’s essential to understand what Ollama and Google Colab are and why they’re valuable tools for working with LLMs.
What is Ollama?
Ollama is an open-source project that simplifies the process of running large language models locally. It provides a user-friendly interface for downloading, running, and managing various LLMs, including popular models like Llama 2, GPT-J, and others. Ollama’s primary goal is to make these powerful models more accessible to developers and researchers who may not have access to high-end hardware.
What is Google Colab?
Google Colab, short for Google Colaboratory, is a free cloud-based platform that allows users to write and execute Python code through a browser. It provides access to powerful computing resources, including GPUs and TPUs, making it an ideal environment for machine learning and data science projects. Colab notebooks are similar to Jupyter notebooks but are hosted in the cloud, eliminating the need for local setup and configuration.
Benefits of Running Ollama on Google Colab
Combining Ollama with Google Colab offers several advantages:
- Free Access to Powerful Hardware: Google Colab provides free access to GPUs, which are essential for running large language models efficiently.
- No Local Setup Required: You can run Ollama without installing anything on your local machine, making it accessible from any device with a web browser.
- Collaborative Environment: Colab notebooks can be easily shared and collaborated on, making it ideal for team projects or educational purposes.
- Flexibility: You can switch between different Ollama models and experiment with various configurations without worrying about local resource constraints.
Setting Up Ollama on Google Colab
Now that we understand the benefits, let’s walk through the process of setting up and running Ollama on Google Colab.
Step 1: Create a New Colab Notebook
- Go to the Google Colab website (colab.research.google.com).
- Click on “New Notebook” to create a new Colab notebook.
Step 2: Install Required Packages
In the first cell of your notebook, we’ll install the necessary packages:
!pip install colab-xterm
%load_ext colabxtermThis installs the colab-xterm package, which allows us to use a terminal within our Colab notebook.
Step 3: Open a Terminal in Colab
To open a terminal within your Colab notebook, run the following command in a new cell:
%xtermThis will open a terminal interface within your notebook, allowing you to run shell commands.
Step 4: Install Ollama
In the terminal that appears, run the following command to install Ollama:
curl -fsSL <https://ollama.com/install.sh> | shThis command downloads and runs the Ollama installation script.
Step 5: Start Ollama Server
After installation, start the Ollama server by running:
ollama serve &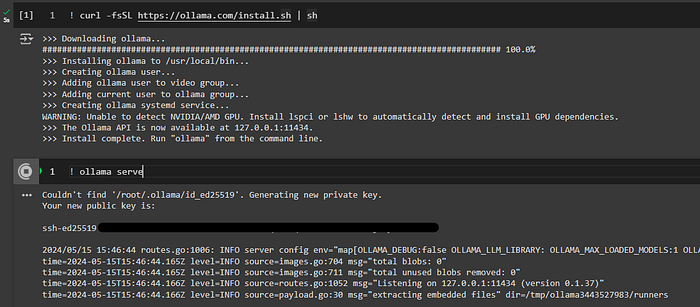
The & at the end runs the server in the background, allowing you to continue using the terminal.
Step 6: Pull an Ollama Model
Now that the Ollama server is running, you can pull a model of your choice. For example, to pull the Llama 2 model, run:
ollama pull llama2Replace llama2 with any other model name you wish to use.
Step 7: Integrate Ollama with LangChain
To use Ollama with LangChain, a popular framework for working with language models, we need to install the LangChain community package:
!pip install langchain_communityStep 8: Set Up Environment Variable
To ensure that LangChain can communicate with our Ollama server, we need to set an environment variable:
import os
os.environ['OLLAMA_HOST'] = '127.0.0.1:11434'Step 9: Using Ollama with LangChain
Now we can use Ollama through LangChain. Here’s a simple example:
from langchain_community.llms import Ollama
# Initialize the Ollama model
llm = Ollama(model="llama2")
# Generate a response
response = llm.invoke("Explain the concept of artificial intelligence in simple terms.")
print(response)This code initializes the Llama 2 model and generates a response to a given prompt.
Best Practices and Tips
When running Ollama on Google Colab, keep the following tips in mind:
- GPU Acceleration: Make sure to select a GPU runtime in Colab for better performance. Go to Runtime > Change runtime type and select GPU as the hardware accelerator.
- Model Selection: Choose models that fit within Colab’s memory constraints. Smaller models like Llama 2 7B are more likely to run smoothly compared to larger variants.
- Session Management: Colab sessions have time limits and may disconnect. Save your work frequently and be prepared to restart your runtime if necessary.
- Resource Monitoring: Keep an eye on your GPU memory usage in Colab. You can view this information in the RAM and GPU widgets at the top right of the notebook.
- Experiment with Different Models: Ollama supports various models. Don’t hesitate to try different ones to find the best fit for your task.
More Things You Can Do with Ollama Running in Google Colab
Now that you’re comfortable with the basic setup, let’s explore more advanced usage scenarios with Ollama on Google Colab, complete with working code samples.
Fine-tuning Models
While Ollama primarily focuses on inference, we can use the models pulled from Ollama as a starting point for fine-tuning on specific tasks. Here’s a practical example of fine-tuning a small language model on a custom dataset:
!pip install transformers datasets torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load a small model from Ollama
model_name = "tinyllama"
!ollama pull {model_name}
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(f"ollama/{model_name}")
model = AutoModelForCausalLM.from_pretrained(f"ollama/{model_name}")
# Prepare a sample dataset (replace with your own dataset)
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=10_000,
save_total_limit=2,
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
trainer.save_model("./fine_tuned_model")This script fine-tunes a small language model on a subset of the WikiText dataset. You can replace the dataset with your own for task-specific fine-tuning.
Integrating with Other Libraries
Let’s integrate Ollama with popular NLP libraries like spaCy and NLTK:
!pip install spacy nltk langchain_community
!python -m spacy download en_core_web_smimport spacy
import nltk
from langchain_community.llms import Ollama
from nltk.tokenize import word_tokenize
nltk.download('punkt')# Initialize Ollama model
llm = Ollama(model="llama2")# Generate text using Ollama
text = llm.invoke("Explain the importance of natural language processing.")# Process with spaCy
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)print("Named Entities:")
for ent in doc.ents:
print(f"{ent.text}: {ent.label_}")# Process with NLTK
tokens = word_tokenize(text)
print("\\\\nTokens:")
print(tokens[:10]) # Print first 10 tokens
This example demonstrates how to generate text with Ollama and then process it using spaCy for named entity recognition and NLTK for tokenization.
Creating Custom Pipelines
Let’s create a custom pipeline for question answering using Ollama and LangChain:
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Initialize Ollama model
llm = Ollama(model="llama2")
# Create a prompt template for question answering
template = """
Context: {context}
Question: {question}
Please provide a concise answer to the question based on the given context.
Answer:"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# Create an LLMChain
qa_chain = LLMChain(llm=llm, prompt=prompt)
# Example usage
context = "The Python programming language was created by Guido van Rossum and first released in 1991. It is known for its simplicity and readability."
question = "Who created Python and when was it first released?"
response = qa_chain.invoke({"context": context, "question": question})
print(response['text'])This pipeline takes a context and a question as input, then generates an answer using the Ollama model through LangChain.
Challenges and Limitations
Let’s address some practical challenges with code examples:
Resource Monitoring
To monitor GPU usage in Colab:
!nvidia-smiRun this command periodically to check GPU memory usage and ensure you’re not exceeding limits.
Handling Session Disconnects
To handle potential session disconnects, you can save your model’s state periodically:
import os
from transformers import AutoModelForCausalLM, AutoTokenizer
def save_model_state(model, tokenizer, path):
if not os.path.exists(path):
os.makedirs(path)
model.save_pretrained(path)
tokenizer.save_pretrained(path)
# Save every 1000 steps during training
if step % 1000 == 0:
save_model_state(model, tokenizer, f"./checkpoint_{step}")
# To resume training
model = AutoModelForCausalLM.from_pretrained("./checkpoint_1000")
tokenizer = AutoTokenizer.from_pretrained("./checkpoint_1000")Version Control for Models
To keep track of model versions:
import json
import datetime
def log_model_version(model_name, description):
log_entry = {
"model_name": model_name,
"timestamp": datetime.datetime.now().isoformat(),
"description": description
}
with open("model_versions.json", "a") as f:
json.dump(log_entry, f)
f.write("\\\\n")
# Usage
log_model_version("llama2-finetuned", "Fine-tuned on custom dataset for improved performance on financial texts")This script maintains a JSON log of model versions and their descriptions.
Conclusion
By providing these practical code examples, we’ve demonstrated how to implement advanced features, integrate with other libraries, create custom pipelines, and address common challenges when running Ollama on Google Colab. These hands-on examples should give you a solid foundation for exploring more complex applications and pushing the boundaries of what’s possible with Ollama and Colab.
Remember to adapt these examples to your specific use cases and datasets. As you continue to experiment and develop, you’ll gain valuable insights into working with large language models in cloud environments. Happy coding, and may your AI projects flourish!

